Datasets
Gaia Sky supports the loading and visualization of datasets and catalogs (used interchangeably in this document) of different nature. Catalogs are groups of similar objects that are loaded and displayed at once.
Contents
Preparing datasets
Please see the STIL data loader section for information about how to prepare the datasets for Gaia Sky.
Loading datasets
Catalogs and datasets can be loaded into Gaia Sky by three different means:
Via SAMP (see this section).
Via scripting (see this section).
Directly using the UI. See the next paragraph.
In order to load a catalog, click on the folder icon ![]() in the controls
window or press ctrl + o and choose the file you want to load. Supported formats are
in the controls
window or press ctrl + o and choose the file you want to load. Supported formats are .csv (Comma-Separated Values),
.vot (VOTable) and FITS (as of 3.0.2). Once the dataset has been chosen, a
new window is presented to the user asking the type of the dataset and some extra options associated with it. This window is also presented when loading a dataset via SAMP.
Hint
As of version 3.0.2, Gaia Sky supports interactive loading of FITS files.
Datasets can be star catalogs, particle datasets, star cluster datasets, or variable star catalogs, depending on whether the new dataset contains stars (with magnitudes, colors, proper motions and whatnot), just particles (only 2D or 3D positions and extra attributes), clusters (with properties like the visual radius) or variable stars (with light curves and periods).
Please, see the Preparing catalogs for more information on how to prepare the datasets for Gaia Sky.
Star catalogs
Star catalogs are expected to contain some attributes of stars, like magnitudes, color indices, proper motions, etc., and use the regular star shaders to render the stars. When selecting star datasets, there are a couple of settings available:
Dataset name – the name of the dataset.
Magnitude scale factor – subtractive scaling factor to apply to the magnitude of all stars (
appmag = appmag - factor).Label color – the color of the labels of the stars in the dataset.
Fade in – these are two distances from the Sun, in parsecs, that will be used as interpolation limits to fade in the whole dataset. The dataset will not be visible if the camera distance from the Sun is smaller than the lower limit, and it will be fully visible if the camera distance from the Sun is larger than the upper limit. The opacity is interpolated between 0 and 1 if the camera distance from the Sun is larger than the lower limit and smaller than the upper limit.
Fade out – these are two distances from the Sun, in parsecs, that will be used as interpolation limits to fade out the whole dataset. The dataset will not be visible if the camera distance from the Sun is larger than the upper limit, and it will be fully visible if the camera distance from the Sun is smaller than the lower limit. The opacity is interpolated between 1 and 0 if the camera distance from the Sun is larger than the lower limit and smaller than the upper limit.
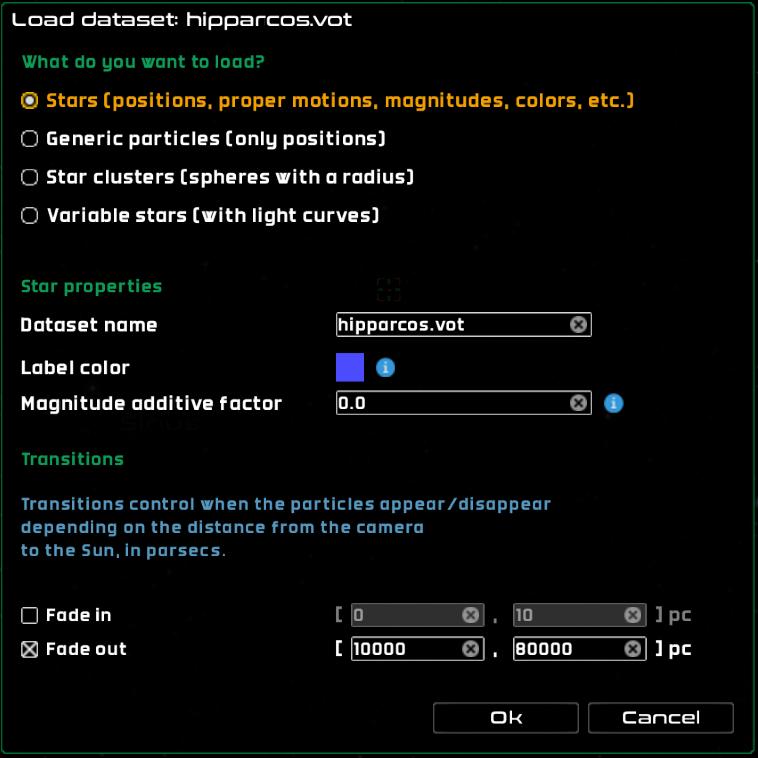
Loading a star catalog
Particle datasets
Particle datasets only require positions to be present, and use generic shaders to render the particles. Some parameters can be tweaked at load time to control the appearance and visibility of the particles:
Dataset name – the name of the dataset.
Particle color – the color of the particles. Can be modified with the particle color noise.
Particle color noise – a value in [0,1] that controls the amount of noise to apply to the particle colors in order to get slightly different colors for each particle in the dataset.
Label color – color of the label of this dataset. Particles themselves do not have individual labels.
Particle size – the size of the particles, in pixels.
Minimum solid angle – the minimum solid angle (in radians) used to represent this particle. This is a minimum bound on the size of the particles.
Maximum solid angle – the maximum solid angle (in radians) used to represent this particle. This is a maximum bound on the size of the particles.
Number of labels – the number of labels to render for this dataset. Set to 0 to render no labels.
Profile decay – a power that controls the radial profile of the actual particles, as in
(1-d)^pow, wheredis the distance from the center to the edge of the particle, in [0,1].Component type – the component type to apply to the particles to control their visibility. Make sure that the chosen component type is enabled in the Visibility pane.
Fade in – these are two distances from the Sun, in parsecs, that will be used as interpolation limits to fade in the whole dataset. The dataset will not be visible if the camera distance from the Sun is smaller than the lower limit, and it will be fully visible if the camera distance from the Sun is larger than the upper limit. The opacity is interpolated between 0 and 1 if the camera distance from the Sun is larger than the lower limit and smaller than the upper limit.
Fade out – these are two distances from the Sun, in parsecs, that will be used as interpolation limits to fade out the whole dataset. The dataset will not be visible if the camera distance from the Sun is larger than the upper limit, and it will be fully visible if the camera distance from the Sun is smaller than the lower limit. The opacity is interpolated between 1 and 0 if the camera distance from the Sun is larger than the lower limit and smaller than the upper limit.
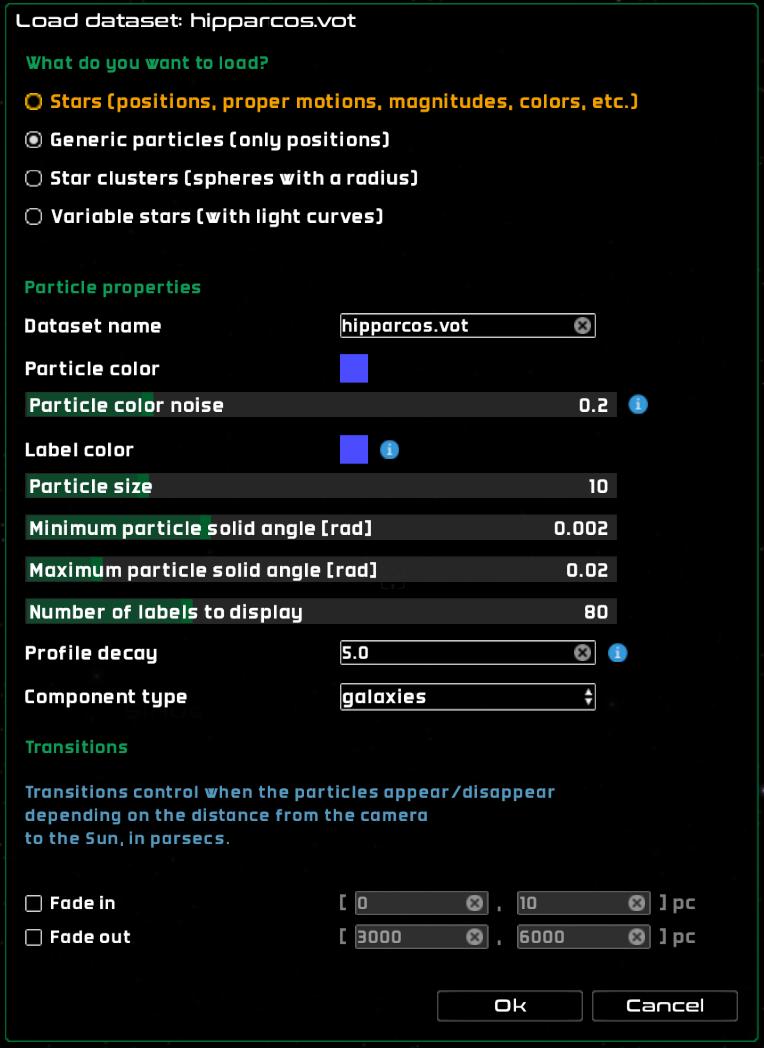
Loading a point cloud dataset
Star cluster catalogs
Star cluster catalogs can also be loaded directly from the UI as of Gaia Sky 2.2.6. The loader also uses STIL to load CSV or VOTable files. In CSV mode the units are fixed, otherwise they are read from the VOTable, if it has them. The order of the columns is not important. The required columns are the following:
name,proper,proper_name,common_name,designation– one or more name strings, separated by ‘|’.ra,alpha,right_ascension– right ascension in degrees.dec,delta,de,declination– declination in degrees.dist,distance– distance to the cluster in parsecs, orpllx,parallax– parallax in mas, if distance is not provided.rcluster,radius– the radius of the cluster in degrees.
Optional columns, which default to zero, include:
pmra,mualpha,pm_ra– proper motion in right ascension, in mas/yr.pmdec,mudelta,pm_dec– proper motion in declination, in mas/yr.rv,radvel,radial_velocity– radial velocity in km/s.
Star cluster datasets require positions and radii to be present, and use wireframe spheres to render the clusters. The parameters that can be tweaked at load time are:
Dataset name – the name of the dataset.
Particle color – the color of the clusters and their labels.
Label color – color of the label of this dataset. Particles themselves do not have individual labels.
Component type – the component type to apply to the particles to control their visibility. Make sure that the chosen component type is enabled in the Visibility pane.
Fade in – these are two distances from the Sun, in parsecs, that will be used as interpolation limits to fade in the whole dataset. The dataset will not be visible if the camera distance from the Sun is smaller than the lower limit, and it will be fully visible if the camera distance from the Sun is larger than the upper limit. The opacity is interpolated between 0 and 1 if the camera distance from the Sun is larger than the lower limit and smaller than the upper limit.
Fade out – these are two distances from the Sun, in parsecs, that will be used as interpolation limits to fade out the whole dataset. The dataset will not be visible if the camera distance from the Sun is larger than the upper limit, and it will be fully visible if the camera distance from the Sun is smaller than the lower limit. The opacity is interpolated between 1 and 0 if the camera distance from the Sun is larger than the lower limit and smaller than the upper limit.
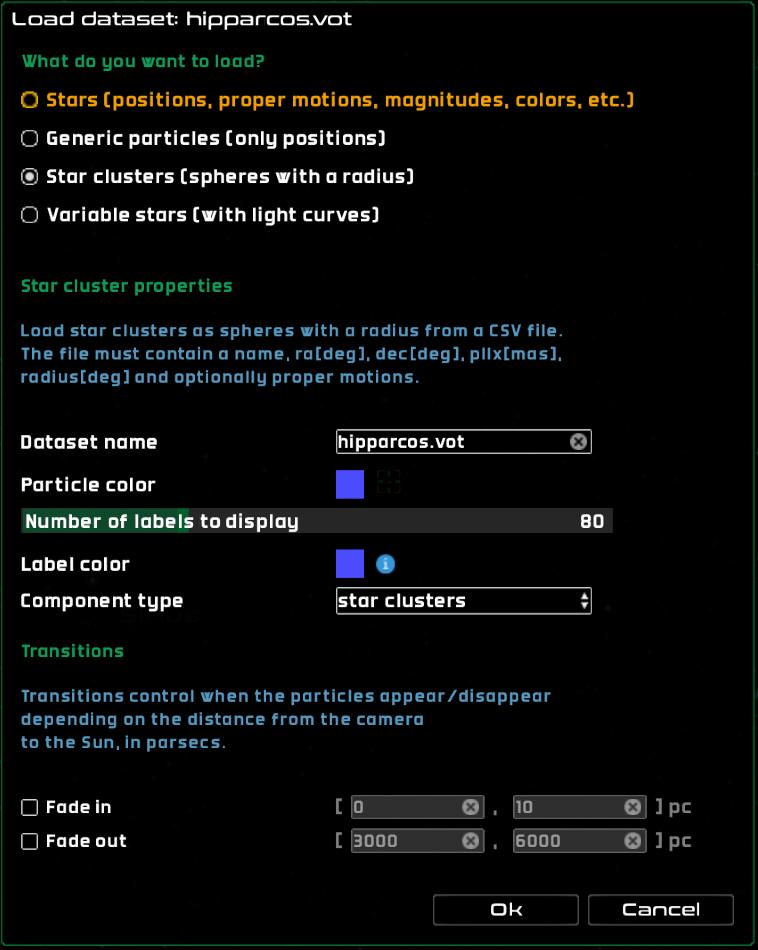
Loading a star cluster catalog
Variable star catalogs
Variable stars are represented in Gaia Sky by displaying the changing magnitude visually in the scene when time is on. These datasets are expected to contain a time series (magnitudes vs times) and a period. Only variable stars with a period are loaded, the rest are discarded.
See the STIL data provider section for more information on how to prepare variable star datasets for Gaia Sky.
Dataset name – the name of the dataset.
Magnitude scale factor – subtractive scaling factor to apply to the magnitude of all stars (
appmag = appmag - factor).Label color – the color of the labels of the stars in the dataset.
Fade in – these are two distances from the Sun, in parsecs, that will be used as interpolation limits to fade in the whole dataset. The dataset will not be visible if the camera distance from the Sun is smaller than the lower limit, and it will be fully visible if the camera distance from the Sun is larger than the upper limit. The opacity is interpolated between 0 and 1 if the camera distance from the Sun is larger than the lower limit and smaller than the upper limit.
Fade out – these are two distances from the Sun, in parsecs, that will be used as interpolation limits to fade out the whole dataset. The dataset will not be visible if the camera distance from the Sun is larger than the upper limit, and it will be fully visible if the camera distance from the Sun is smaller than the lower limit. The opacity is interpolated between 1 and 0 if the camera distance from the Sun is larger than the lower limit and smaller than the upper limit.
The process by which light curves are loaded and used in Gaia Sky is a bit involved and outlined below:
First, we check that time series (magnitudes v times) and periods are actually present in the file.
Then, NaN values are removed from the light curve data points.
We fold the time series into a phase diagram using the period and sort the result accordingly with the phase for each data point.
Due to a GPU memory trade-off (the time series data must be sent to the GPU for each star, and all stars must have the same in-memory size in the GPU), we have a limitation of 20 data points per star. If the number of incoming data points is larger than 20, we re-sample the phase diagram.
Finally, the magnitudes are converted to pseudo-sizes for easier representation, and passed on to the model.
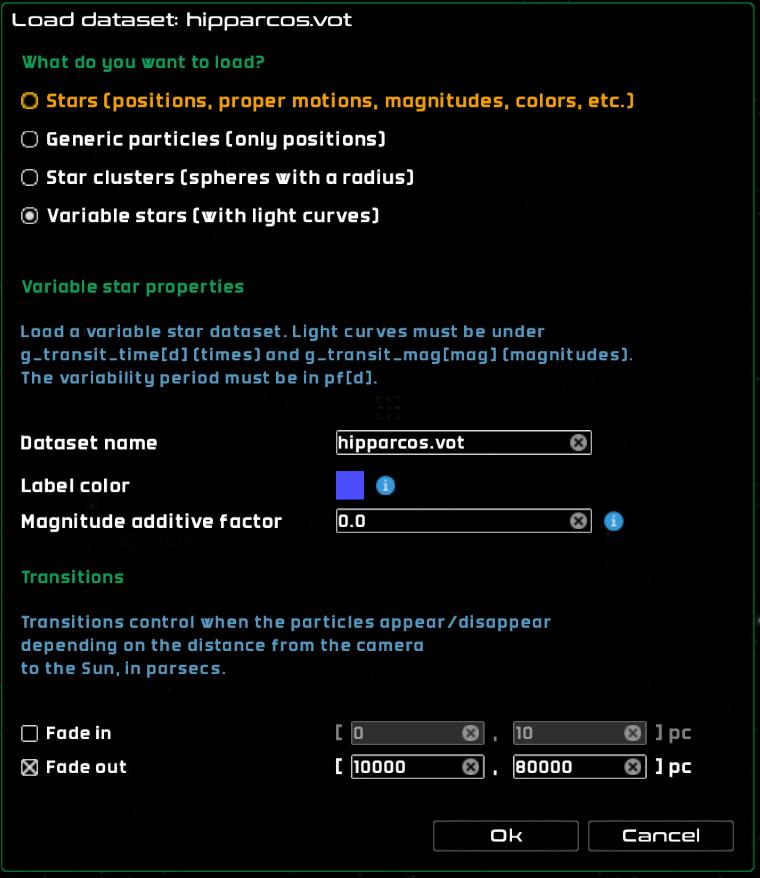
Loading a variable star catalog
Datasets pane
You can find a list of all datasets currently loaded in the Datasets pane, anchored to the top-left of the screen. You can bring it up automatically by pressing d.
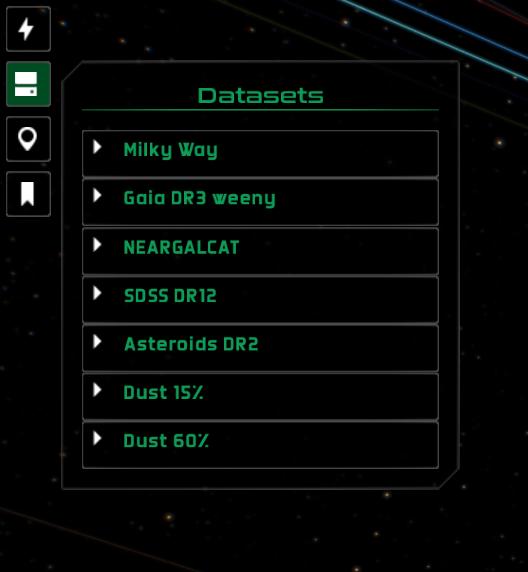
Datasets pane in Gaia Sky
Each dataset has a panel that can be expanded by clicking on the ![]() icon by the dataset name. Once expanded, a dataset panel can be collapsed with
icon by the dataset name. Once expanded, a dataset panel can be collapsed with ![]() .
.
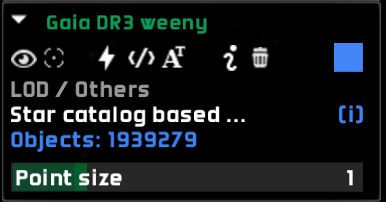
Dataset panel in the datasets pane for the ‘Gaia DR3 weeny’ catalog
The dataset panel, once expanded, contains a few controls that depend on the type of dataset, and that allow the user to modify some settings about how the dataset is displayed. These controls are in the topmost line in the dataset pane. From left to right, the controls are the following:
 – toggle the visibility of the dataset. This makes the whole dataset appear and disappear.
– toggle the visibility of the dataset. This makes the whole dataset appear and disappear. – highlight the dataset using the current color and particle size. The color can be changed by clicking on the rightmost button (blue square in the image above), and the particle size factor can be adjusted from the dataset visual settings window. Datasets can also be color-mapped. Only star, particle, LOD and orbital elements datasets can be highlighted.
– highlight the dataset using the current color and particle size. The color can be changed by clicking on the rightmost button (blue square in the image above), and the particle size factor can be adjusted from the dataset visual settings window. Datasets can also be color-mapped. Only star, particle, LOD and orbital elements datasets can be highlighted. – open the dataset visual settings window.
– open the dataset visual settings window. – open the dataset filters window.
– open the dataset filters window. – open the dataset affine transformations window.
– open the dataset affine transformations window. – open the dataset information window.
– open the dataset information window. – delete the dataset.
– delete the dataset.
After the controls, we can find some information:
The type of dataset, in gray.
The dataset description, if any. Move your mouse to the small (i) symbol to get the full description in a tooltip.
The number of objects in the dataset, in blue.
Dataset highlighting
Datasets can be highlighted by clicking on the target icon . When highlighted, the colors of the particles change according to the highlighting color or color map selected (see below), and the particles may also become larger or smaller depending on the settings in the highlight section of the visual settings dialog.
To the right of the dataset pane is the color icon. Use it to define the highlight color for the dataset. The color can either be a plain color or a color map.
A plain color can be chosen using the color picker dialog that appears when clicking on the “Plain color” radio button.
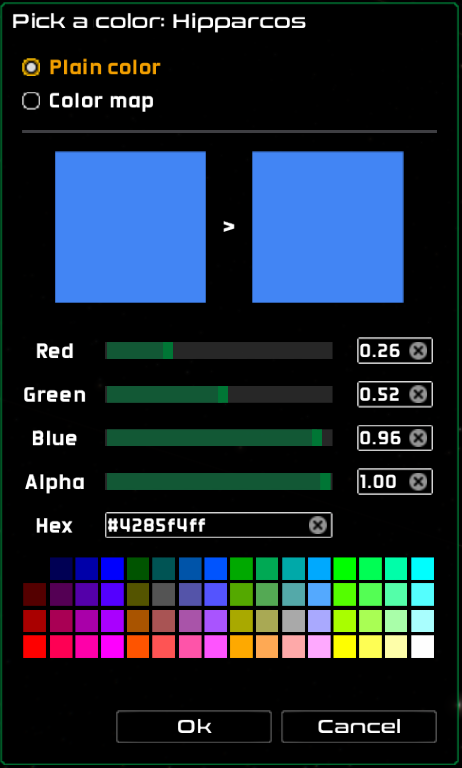
The highlighting plain color picker dialog
A color map can be selected by clicking on the “Color map” radio button, and displays the screen shown below. From there, you can choose the color map type, as well as the attribute to use for the mapping, and the maximum and minimum mapping values.
The available attributes depend on the dataset type and loading method. Particle datasets have coordinate attributes (right ascension, declination, ecliptic longitude and latitude, galactic longitude and latitude) and distance distance. Star datasets have, additionally, apparent and absolute magnitudes, proper motions (in alpha and delta) and radial velocity. For all datasets loaded from VOTable either directly or through SAMP, all the numeric attributes are also available
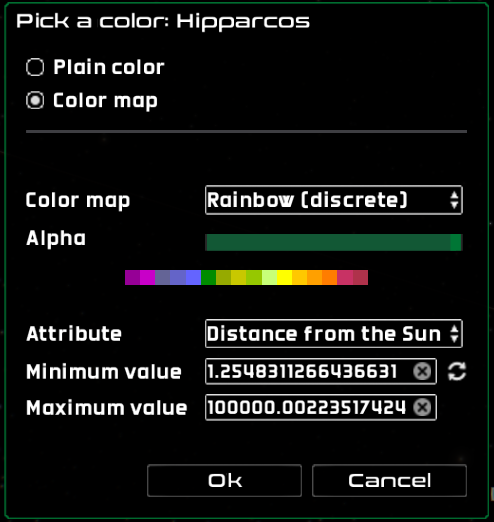
The highlighting color map dialog
Dataset visual settings
Open the dataset visual settings window by clicking on the bolt icon . There are three sections, named particle aspect, highlighting and transitions.
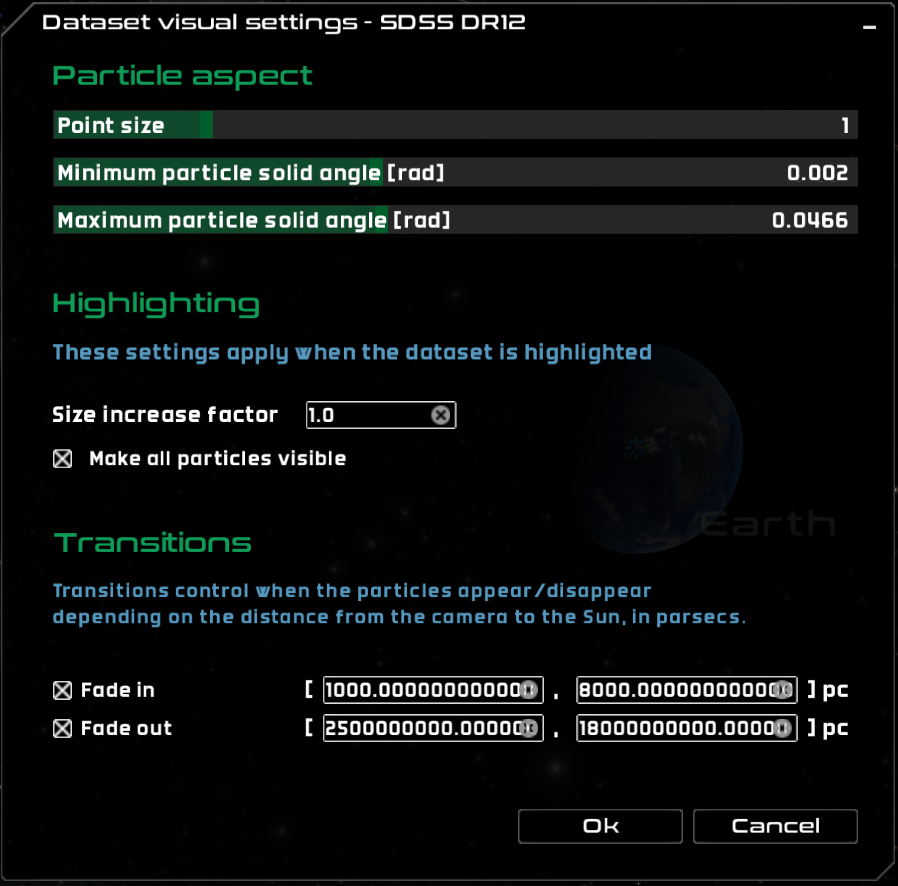
The dataset visual settings dialog
In the particle aspect section we can find the following controls:
Point size – this slider controls the dataset point size. This acts as a factor on the actual size of the particles of the dataset.
Minimum particle solid angle [rad] – only present in particle datasets, this slider controls the minimum visual solid angle of each particle.
Maximum particle solid angle [rad] – only present in particle datasets, this slider controls the maximum visual solid angle of each particle.
In the highlighting section, we can find the following properties:
Size increase factor - scale factor to apply to the particles when the dataset is highlighted.
Make all particles visible - raises the minimum opacity to a non-zero value when the dataset is highlighted.
In the Transitions section, we can define fade-in and fade-out rules depending on the distance from the camera to the center of the dataset, or to the center of the reference system.
Fade in – this check box enables the fade-in transitions, where the dataset opacity goes from 0 (invisible) to 1 (fully visible), mapped to the user given-distances in parsecs.
Fade out – this check box enables the fade-out transitions, where the dataset opacity goes from 1 (fully visible) to 0 (invisible), mapped to the user given-distances in parsecs.
Dataset filters
Open the dataset filters window by clicking on the code icon . Filters are only available to particle, stars and LOD datasets.
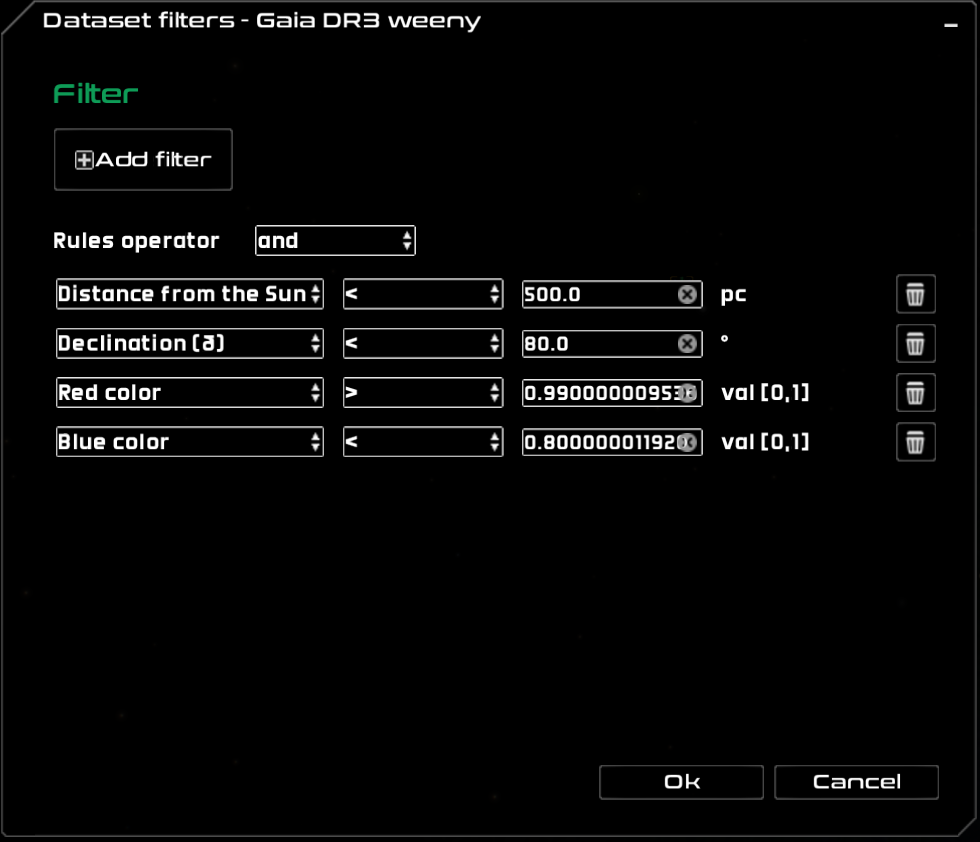
The dataset filters dialog
This dialog allows for the creation of arbitrary selection filters by setting conditions (rules) on particle attributes. Several rules can be defined, but only one type of logical operator (AND, OR) is possible. The available attributes depend on the dataset type and loading method.
Click on the ![]() Add filter button to add a filter, and use
Add filter button to add a filter, and use ![]() Add rule to add new rules to the current filter. The Rules operator select box enables the selection of the logical operator. Then, each rule contains the attribute, the comparator operation (<, <=, >, >=, ==, !=) and a value. Use the bin icon
Add rule to add new rules to the current filter. The Rules operator select box enables the selection of the logical operator. Then, each rule contains the attribute, the comparator operation (<, <=, >, >=, ==, !=) and a value. Use the bin icon ![]() to delete a rule.
to delete a rule.
Dataset transformations
The dataset transformations window (open it by clicking on the matrix icon ![]() ) enables the definition of arbitrary affine transformations (only translation, rotation and scaling available, plus reference system transforms) and application to the datasets in real time. Transformations are available to all datasets, but only particles in groups will be affected. Single objects (models, single stars, planets, moons, etc.) that are part of a dataset are not applied the transformations.
) enables the definition of arbitrary affine transformations (only translation, rotation and scaling available, plus reference system transforms) and application to the datasets in real time. Transformations are available to all datasets, but only particles in groups will be affected. Single objects (models, single stars, planets, moons, etc.) that are part of a dataset are not applied the transformations.

The dataset transformations dialog
Transformations are defined in a sequence. Each transformation is represented by a matrix. The matrices are multiplied in the defined order. This means that the transformations are actually applied last-to-first. If you want to rotate a dataset, and then translate it, you need to first define a translation and then a rotation.
Add a new transformation by clicking on the ![]() Add transformation button. Once the transformation appears, there are a few settings you can change:
Add transformation button. Once the transformation appears, there are a few settings you can change:
Type – select the transformation type: translation, rotation, scaling or reference system.
 – move the transformation up in the chain.
– move the transformation up in the chain. – move the transformation down in the chain.
– move the transformation down in the chain.- – remove the transformation.
For each transformation type we have different inputs:
Translation – choose the X, Y and Z of your translation vector, in parsecs.
Rotation – choose the rotation axis X, Y and Z components, plus the rotation angle, in degrees.
Scaling – choose the scaling factor in X, Y and Z. No units here.
Reference system – select the reference system transformation you want to apply from the select box. The possible transformations are:
Galactic to equatorial
Equatorial to galactic
Ecliptic to equatorial
Equatorial to ecliptic
Galactic to ecliptic
Ecliptic to galactic
Dataset inforamtion
Get some additional information on a dataset by clicking on the ‘i’ icon .
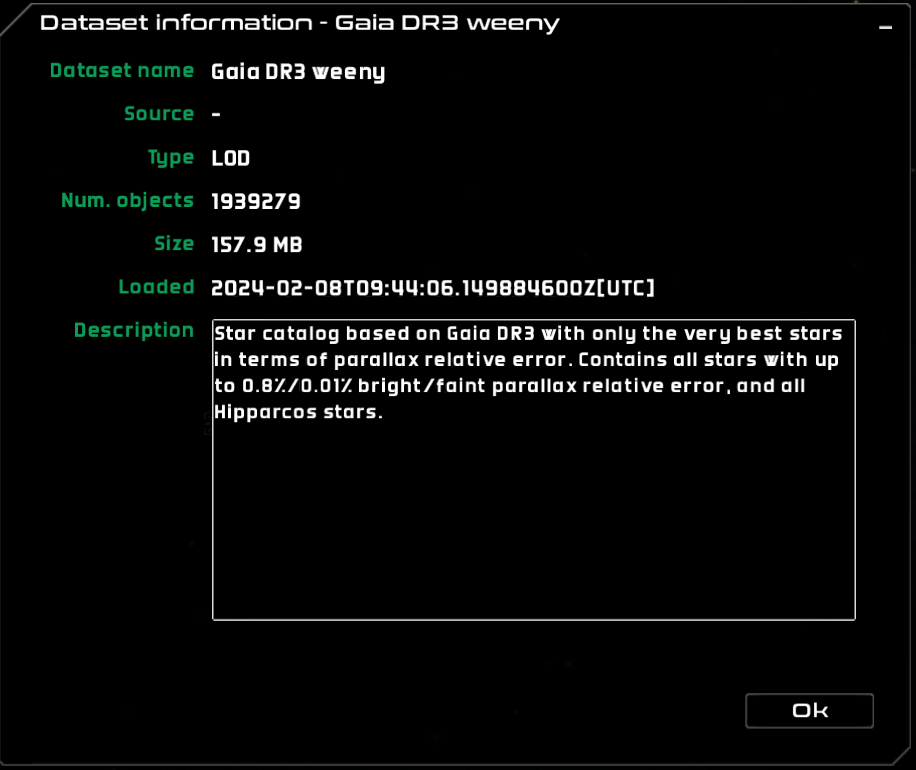
The dataset information dialog
For each dataset you get:
Dataset name – the name of the dataset.
Source – the source. Only populated if the dataset is loaded from the UI or via SAMP.
Type – the type of dataset.
Num. objects – the number of objects in the dataset.
Size – the size in disk.
Loaded – exact time when the dataset was loaded.
Description – dataset description.